 java.lang.String
java.lang.String
|
JavaTM Platform Standard Ed. 6 |
|||||||||
| 前のクラス 次のクラス | フレームあり フレームなし | |||||||||
| 概要: 入れ子 | フィールド | コンストラクタ | メソッド | 詳細: フィールド | コンストラクタ | メソッド | |||||||||
java.lang.Object
public final class String
String クラスは文字列を表します。Java プログラム内の「abc」などのリテラル文字列はすべて、このクラスのインスタンスとして実行されます。
文字列は定数です。 この値を作成したあとに変更はできません。文字列バッファーは可変文字列をサポートします。文字列オブジェクトは不変であるため、共用することができます。次に例を示します。
String str = "abc";
これは、次と同じです。
char data[] = {'a', 'b', 'c'};
String str = new String(data);
文字列がどのように使われるかについて、さらに例を示します。
System.out.println("abc");
String cde = "cde";
System.out.println("abc" + cde);
String c = "abc".substring(2,3);
String d = cde.substring(1, 2);
String クラスには、文字列のそれぞれの文字をテストするメソッドや、文字列の比較、文字列の検索、部分文字列の抽出、および文字をすべて大文字または小文字に変換した文字列のコピー作成などを行うメソッドがあります。ケースマッピングは、Character クラスで指定された Unicode 仕様バージョンに基づいています。
Java 言語は、文字列連結演算子 ( + )、およびその他のオブジェクトから文字列への変換に対する特別なサポートを提供します。文字列連結は StringBuilder (または StringBuffer) クラスとその append メソッドを使って実装されています。文字列変換は Object によって定義された toString メソッドを使って実装され、Java のクラスすべてによって継承されます。文字列連結および文字列変換についての詳細は、Gosling、Joy、および Steele による『Java 言語仕様』を参照してください。
ほかで指定がない場合、null 引数をコンストラクタ、またはこのクラスのメソッドへ渡すと NullPointerException がスローされます。
String は、「補助文字」を「サロゲートペア」で表現する UTF-16 形式の文字列を表します (詳細は、Character クラスの「Unicode 文字表現」のセクションを参照)。char コード単位を参照するインデックス値です。 したがって、補助文字は String の 2 つの位置を使用します。
String クラスは、Unicode コード単位 (char 値) を扱うメソッドのほかに、Unicode コードポイント (文字) を扱うメソッドを提供します。
Object.toString(),
StringBuffer,
StringBuilder,
Charset,
直列化された形式| フィールドの概要 | |
|---|---|
static Comparator<String> |
CASE_INSENSITIVE_ORDER
compareToIgnoreCase の場合と同じように String オブジェクトを順序付ける Comparator です。 |
| コンストラクタの概要 | |
|---|---|
String()
新しく生成された String オブジェクトを初期化して、空の文字シーケンスを表すようにします。 |
|
String(byte[] bytes)
プラットフォームのデフォルトの文字セットを使用して、指定されたバイト配列を復号化することによって、新しい String を構築します。 |
|
String(byte[] bytes,
Charset charset)
指定された 文字セット を使用して、指定されたバイト配列を復号化することによって、新しい String を構築します。 |
|
String(byte[] ascii,
int hibyte)
推奨されていません。 このメソッドでは、バイトから文字への変換が正しく行われません。 JDK 1.1 以降では、バイトから文字への変換には、引数として Charset、文字セットの名前を取る String コンストラクタ、またはプラットフォームのデフォルト文字セットを使用する String コンストラクタの使用が推奨されます。 |
|
String(byte[] bytes,
int offset,
int length)
プラットフォームのデフォルトの文字セットを使用して、指定されたバイト部分配列を復号化することによって、新しい String を構築します。 |
|
String(byte[] bytes,
int offset,
int length,
Charset charset)
指定された charset を使用して、指定されたバイト部分配列を復号化することによって、新しい String を構築します。 |
|
String(byte[] ascii,
int hibyte,
int offset,
int count)
推奨されていません。 このメソッドでは、バイトから文字への変換が正しく行われません。 JDK 1.1 以降では、バイトから文字への変換には、引数として Charset、文字セットの名前を取る String コンストラクタ、またはプラットフォームのデフォルト文字セットを使用する String コンストラクタの使用が推奨されます。 |
|
String(byte[] bytes,
int offset,
int length,
String charsetName)
指定された文字セットを使用して、指定されたバイト部分配列を復号化することによって、新しい String を構築します。 |
|
String(byte[] bytes,
String charsetName)
指定された 文字セット を使用して、指定されたバイト配列を復号化することによって、新しい String を構築します。 |
|
String(char[] value)
新しい String を割り当てて、これが文字配列引数に現在含まれている文字シーケンスを表すようにします。 |
|
String(char[] value,
int offset,
int count)
文字配列引数の部分配列からなる文字を含む新しい String を割り当てます。 |
|
String(int[] codePoints,
int offset,
int count)
Unicode コードポイント配列引数の部分配列からなる文字を含む新しい String を割り当てます。 |
|
String(String original)
新しく生成された String オブジェクトを初期化して、引数と同じ文字シーケンスを表すようにします。 |
|
String(StringBuffer buffer)
文字列バッファー引数に現在含まれている文字列を持つ新しい文字列を構築します。 |
|
String(StringBuilder builder)
文字列ビルダー引数に現在含まれている文字列を持つ新しい文字列を割り当てます。 |
|
| メソッドの概要 | |
|---|---|
char |
charAt(int index)
指定されたインデックス位置にある char 値を返します。 |
int |
codePointAt(int index)
指定されたインデックス位置の文字 (Unicode コードポイント) を返します。 |
int |
codePointBefore(int index)
指定されたインデックスの前の文字 (Unicode コードポイント) を返します。 |
int |
codePointCount(int beginIndex,
int endIndex)
この String の指定されたテキスト範囲の Unicode コードポイントの数を返します。 |
int |
compareTo(String anotherString)
2 つの文字列を辞書的に比較します。 |
int |
compareToIgnoreCase(String str)
大文字と小文字の区別なしで、2 つの文字列を辞書的に比較します。 |
String |
concat(String str)
指定された文字列をこの文字列の最後に連結します。 |
boolean |
contains(CharSequence s)
この文字列が指定された char 値のシーケンスを含む場合に限り true を返します。 |
boolean |
contentEquals(CharSequence cs)
この文字列と指定された CharSequence を比較します。 |
boolean |
contentEquals(StringBuffer sb)
この文字列と指定された StringBuffer を比較します。 |
static String |
copyValueOf(char[] data)
指定された配列内の文字シーケンスを表す String を返します。 |
static String |
copyValueOf(char[] data,
int offset,
int count)
指定された配列内の文字シーケンスを表す String を返します。 |
boolean |
endsWith(String suffix)
この文字列が、指定された接尾辞で終るかどうかを判定します。 |
boolean |
equals(Object anObject)
この文字列と指定されたオブジェクトを比較します。 |
boolean |
equalsIgnoreCase(String anotherString)
この String とほかの String を比較します。 |
static String |
format(Locale l,
String format,
Object... args)
指定されたロケール、書式文字列、および引数を使って、フォーマットされた文字列を返します。 |
static String |
format(String format,
Object... args)
指定された書式の文字列と引数を使って、書式付き文字列を返します。 |
byte[] |
getBytes()
プラットフォームのデフォルトの文字セットを使用してこの String をバイトシーケンスに符号化し、結果を新規バイト配列に格納します。 |
byte[] |
getBytes(Charset charset)
指定された 文字セット を使用してこの String をバイトシーケンスに符号化し、結果を新規バイト配列に格納します。 |
void |
getBytes(int srcBegin,
int srcEnd,
byte[] dst,
int dstBegin)
推奨されていません。 このメソッドでは、文字からバイトへの変換が正しく行われません。 JDK 1.1 では、文字からバイトへの変換には、プラットフォームのデフォルト文字セットを使用する getBytes() メソッドの使用が推奨されます。 |
byte[] |
getBytes(String charsetName)
指定された文字セットを使用してこの String をバイトシーケンスに符号化し、結果を新規バイト配列に格納します。 |
void |
getChars(int srcBegin,
int srcEnd,
char[] dst,
int dstBegin)
この文字列から、コピー先の文字配列に文字をコピーします。 |
int |
hashCode()
この文字列のハッシュコードを返します。 |
int |
indexOf(int ch)
この文字列内で、指定された文字が最初に出現する位置のインデックスを返します。 |
int |
indexOf(int ch,
int fromIndex)
この文字列内で、指定されたインデックスから検索を開始し、指定された文字が最初に出現する位置のインデックスを返します。 |
int |
indexOf(String str)
この文字列内で、指定された部分文字列が最初に出現する位置のインデックスを返します。 |
int |
indexOf(String str,
int fromIndex)
指定されたインデックス以降で、指定された部分文字列がこの文字列内で最初に出現する位置のインデックスを返します。 |
String |
intern()
文字列オブジェクトの正規の表現を返します。 |
boolean |
isEmpty()
length() が 0 である場合にかぎり、true を返します。 |
int |
lastIndexOf(int ch)
この文字列内で、指定された文字が最後に出現する位置のインデックスを返します。 |
int |
lastIndexOf(int ch,
int fromIndex)
この文字列内で、指定された文字が最後に出現する位置のインデックスを返します (検索は指定されたインデックスから開始され、先頭方向に行われる)。 |
int |
lastIndexOf(String str)
この文字列内で、指定された部分文字列が一番右に出現する位置のインデックスを返します。 |
int |
lastIndexOf(String str,
int fromIndex)
この文字列内で、指定された部分文字列が最後に出現する位置のインデックスを返します (検索は指定されたインデックスから開始され、先頭方向に行われる)。 |
int |
length()
この文字列の長さを返します。 |
boolean |
matches(String regex)
この文字列が、指定された正規表現と一致するかどうかを判定します。 |
int |
offsetByCodePoints(int index,
int codePointOffset)
codePointOffset コードポイントによって指定された index からオフセットが設定された、この String 内のインデックスを返します。 |
boolean |
regionMatches(boolean ignoreCase,
int toffset,
String other,
int ooffset,
int len)
2 つの文字列領域が等しいかどうかを判定します。 |
boolean |
regionMatches(int toffset,
String other,
int ooffset,
int len)
2 つの文字列領域が等しいかどうかを判定します。 |
String |
replace(char oldChar,
char newChar)
この文字列内にあるすべての oldChar を newChar に置換した結果生成される、新しい文字列を返します。 |
String |
replace(CharSequence target,
CharSequence replacement)
リテラルターゲットシーケンスに一致するこの文字列の部分文字列を、指定されたリテラル置換シーケンスに置き換えます。 |
String |
replaceAll(String regex,
String replacement)
指定された正規表現に一致する、この文字列の各部分文字列に対し、指定された置換を実行します。 |
String |
replaceFirst(String regex,
String replacement)
指定された正規表現に一致する、この文字列の最初の部分文字列に対し、指定された置換を実行します。 |
String[] |
split(String regex)
この文字列を、指定された正規表現に一致する位置で分割します。 |
String[] |
split(String regex,
int limit)
この文字列を、指定された正規表現に一致する位置で分割します。 |
boolean |
startsWith(String prefix)
この文字列が、指定された接頭辞で始まるかどうかを判定します。 |
boolean |
startsWith(String prefix,
int toffset)
この文字列の指定されたインデックス以降の部分文字列が、指定された接頭辞で始まるかどうかを判定します。 |
CharSequence |
subSequence(int beginIndex,
int endIndex)
このシーケンスのサブシーケンスである新規文字シーケンスを返します。 |
String |
substring(int beginIndex)
この文字列の部分文字列である新しい文字列を返します。 |
String |
substring(int beginIndex,
int endIndex)
この文字列の部分文字列である新しい文字列を返します。 |
char[] |
toCharArray()
この文字列を新しい文字配列に変換します。 |
String |
toLowerCase()
デフォルトロケールの規則を使って、この String 内のすべての文字を小文字に変換します。 |
String |
toLowerCase(Locale locale)
指定された Locale の規則を使用して、この String 内のすべての文字列を小文字に変換します。 |
String |
toString()
このオブジェクト (すでに文字列である) 自身が返されます。 |
String |
toUpperCase()
デフォルトロケールの規則を使って、この String 内のすべての文字を大文字に変換します。 |
String |
toUpperCase(Locale locale)
指定された Locale の規則を使用して、この String 内のすべての文字列を大文字に変換します。 |
String |
trim()
文字列のコピーを返します。 |
static String |
valueOf(boolean b)
boolean 引数の文字列表現を返します。 |
static String |
valueOf(char c)
char 引数の文字列表現を返します。 |
static String |
valueOf(char[] data)
char 配列引数の文字列表現を返します。 |
static String |
valueOf(char[] data,
int offset,
int count)
char 配列引数の特定の部分配列の文字列表現を返します。 |
static String |
valueOf(double d)
double 引数の文字列表現を返します。 |
static String |
valueOf(float f)
float 引数の文字列表現を返します。 |
static String |
valueOf(int i)
int 引数の文字列表現を返します。 |
static String |
valueOf(long l)
long 引数の文字列表現を返します。 |
static String |
valueOf(Object obj)
Object 引数の文字列表現を返します。 |
| クラス java.lang.Object から継承されたメソッド |
|---|
clone, finalize, getClass, notify, notifyAll, wait, wait, wait |
| フィールドの詳細 |
|---|
public static final Comparator<String> CASE_INSENSITIVE_ORDER
compareToIgnoreCase の場合と同じように String オブジェクトを順序付ける Comparator です。このコンパレータは直列化可能です。 この Comparator はロケールを考慮しないので、一部のロケールでは、正しい順序に並べられないことがあります。java.text パッケージは、ロケールに依存する並べ替えを行うために「照合機能」を提供しています。
Collator.compare(String, String)| コンストラクタの詳細 |
|---|
public String()
String オブジェクトを初期化して、空の文字シーケンスを表すようにします。String は不変なので、このコンストラクタを使う必要はありません。
public String(String original)
String オブジェクトを初期化して、引数と同じ文字シーケンスを表すようにします。つまり、新しく作成された文字列は引数文字列のコピーになります。String は不変なので、original の明示的なコピーが必要でないかぎり、このコンストラクタを使う必要はありません。
original - Stringpublic String(char[] value)
String を割り当てて、これが文字配列引数に現在含まれている文字シーケンスを表すようにします。文字配列の内容がコピーされます。 コピー後にその文字が変更されても、新しく作成された文字列には影響しません。
value - 文字列の初期値
public String(char[] value,
int offset,
int count)
String を割り当てます。引数 offset は部分配列の先頭の文字のインデックスであり、引数 count は部分配列の長さを指定します。 部分配列の内容がコピーされます。部分配列の内容がコピーされます。 コピー後に文字配列が変更されても、新しく作成された文字列には影響しません。
value - 文字列のソースである配列offset - 初期オフセットcount - 長さ
IndexOutOfBoundsException - offset および count 引数インデックスによる文字列が value 配列の範囲外となる場合
public String(int[] codePoints,
int offset,
int count)
String を割り当てます。引数 offset は部分配列の先頭のコードポイントのインデックスであり、引数 count は部分配列の長さを指定します。部分配列の内容がコピーされます。部分配列の内容は、char に変換されます。 コピー後に int 配列が変更されても、新しく作成された文字列には影響しません。
codePoints - Unicode コードポイントのソースである配列offset - 初期オフセットcount - 長さ
IllegalArgumentException - codePoints で無効な Unicode コードポイントが見つかった場合
IndexOutOfBoundsException - offset および count 引数インデックスによる文字列が codePoints 配列の範囲外となる場合
@Deprecated
public String(byte[] ascii,
int hibyte,
int offset,
int count)
Charset、文字セットの名前を取る String コンストラクタ、またはプラットフォームのデフォルト文字セットを使用する String コンストラクタの使用が推奨されます。
String を割り当てます。
引数 offset は部分配列の先頭のバイトのインデックスであり、引数 count は部分配列の長さを指定します。 部分配列の内容がコピーされます。
部分配列の各 byte は上記メソッドに指定される char に変換されます。
ascii - 文字列に変換されるバイトhibyte - 16 ビットの各 Unicode コード 単位の上位 8 ビットoffset - 初期オフセットcount - 長さ
IndexOutOfBoundsException - offset または count 引数が無効な場合String(byte[], int),
String(byte[], int, int, java.lang.String),
String(byte[], int, int, java.nio.charset.Charset),
String(byte[], int, int),
String(byte[], java.lang.String),
String(byte[], java.nio.charset.Charset),
String(byte[])
@Deprecated
public String(byte[] ascii,
int hibyte)
Charset、文字セットの名前を取る String コンストラクタ、またはプラットフォームのデフォルト文字セットを使用する String コンストラクタの使用が推奨されます。
String を割り当てます。結果として得られる文字列のそれぞれの文字 c は、以下のようなバイト配列内の対応する要素 b から構成されます。
c == (char)(((hibyte & 0xff) << 8)
| (b & 0xff))
ascii - 文字列に変換されるバイトhibyte - 16 ビットの各 Unicode コード 単位の上位 8 ビットString(byte[], int, int, java.lang.String),
String(byte[], int, int, java.nio.charset.Charset),
String(byte[], int, int),
String(byte[], java.lang.String),
String(byte[], java.nio.charset.Charset),
String(byte[])
public String(byte[] bytes,
int offset,
int length,
String charsetName)
throws UnsupportedEncodingException
String を構築します。新しい String の長さは文字セットによって変化するため、部分配列長と一致しないことがあります。
指定された文字セットで指定されたバイトが無効な場合、このコンストラクタの動作は指定されません。復号化処理をより強力に制御する必要がある場合、CharsetDecoder クラスを使用する必要があります。
bytes - 文字列に復号化されるバイトoffset - 復号化される先頭バイトのインデックスlength - 復号化するバイト数charsetName - サポートする charset の名前
UnsupportedEncodingException - 指定された文字セットがサポートされていない場合
IndexOutOfBoundsException - offset および length 引数インデックスによる文字列が bytes 配列の範囲外となる場合
public String(byte[] bytes,
int offset,
int length,
Charset charset)
String を構築します。新しい String の長さは文字セットによって変化するため、部分配列長と一致しないことがあります。
このメソッドは、不正入力シーケンスやマップ不可文字シーケンスを、この文字セットのデフォルトの置換文字列で置き換えます。復号化処理をより強力に制御する必要がある場合、CharsetDecoder クラスを使用する必要があります。
bytes - 文字列に復号化されるバイトoffset - 復号化される先頭バイトのインデックスlength - 復号化するバイト数charset - bytes の復号化に使用される 文字セット
IndexOutOfBoundsException - offset および length 引数インデックスによる文字列が bytes 配列の範囲外となる場合
public String(byte[] bytes,
String charsetName)
throws UnsupportedEncodingException
String を構築します。新しい String の長さは文字セットによって変化するため、バイト配列長と一致しないことがあります。
指定された文字セットで指定されたバイトが無効な場合、このコンストラクタの動作は指定されません。復号化処理をより強力に制御する必要がある場合、CharsetDecoder クラスを使用する必要があります。
bytes - 文字列に復号化されるバイトcharsetName - サポートする charset の名前
UnsupportedEncodingException - 指定された文字セットがサポートされていない場合
public String(byte[] bytes,
Charset charset)
String を構築します。新しい String の長さは文字セットによって変化するため、バイト配列長と一致しないことがあります。
このメソッドは、不正入力シーケンスやマップ不可文字シーケンスを、この文字セットのデフォルトの置換文字列で置き換えます。復号化処理をより強力に制御する必要がある場合、CharsetDecoder クラスを使用する必要があります。
bytes - 文字列に復号化されるバイトcharset - bytes の復号化に使用される 文字セット
public String(byte[] bytes,
int offset,
int length)
String を構築します。新しい String の長さは文字セットによって変化するため、部分配列長と一致しないことがあります。
指定されたバイトがデフォルトの文字セットで無効な場合、このコンストラクタの動作は指定されません。復号化処理をより強力に制御する必要がある場合、CharsetDecoder クラスを使用する必要があります。
bytes - 文字列に復号化されるバイトoffset - 復号化される先頭バイトのインデックスlength - 復号化するバイト数
IndexOutOfBoundsException - offset および length 引数インデックスによる文字列が bytes 配列の範囲外となる場合public String(byte[] bytes)
String を構築します。新しい String の長さは文字セットによって変化するため、バイト配列長と一致しないことがあります。
指定されたバイトがデフォルトの文字セットで無効な場合、このコンストラクタの動作は指定されません。復号化処理をより強力に制御する必要がある場合、CharsetDecoder クラスを使用する必要があります。
bytes - 文字列に復号化されるバイトpublic String(StringBuffer buffer)
buffer - StringBufferpublic String(StringBuilder builder)
このコンストラクタを使用すると、StringBuilder に移行しやすくなります。toString メソッドを使って文字列ビルダーから文字列を取得するのは、処理が高速になるので一般的に推奨されています。
builder - StringBuilder| メソッドの詳細 |
|---|
public int length()
CharSequence 内の lengthpublic boolean isEmpty()
length() が 0 である場合にかぎり、true を返します。
length() が 0 の場合は true、そうでない場合は falsepublic char charAt(int index)
char 値を返します。インデックスは、0 から length() - 1 の範囲になります。配列のインデックス付けの場合と同じように、シーケンスの最初の char 値のインデックスは 0、次の文字のインデックスは 1 と続きます。
インデックスで指定された char 値がサロゲートの場合、サロゲート値が返されます。
CharSequence 内の charAtindex - char 値のインデックス
char 値。
最初の char 値のインデックスが 0 になる
IndexOutOfBoundsException - index 引数が負の値、または文字列の長さと同じかこれより大きい値の場合public int codePointAt(int index)
char 値 (Unicode コード単位) を参照し、範囲は 0 〜 length() - 1 です。
指定されたインデックスで指定された char 値が上位サロゲート範囲にある場合、それに続くインデックスは、このString の長さ未満です。 また、以降のインデックスの char 値が下位サロゲート範囲にある場合、このサロゲートペアに対応する補助コードポイントが返されます。そうでない場合、指定されたインデックスにある char 値が返されます。
index - char 値のインデックス
index にある文字のコードポイント値
IndexOutOfBoundsException - index 引数が負の値、または文字列の長さと同じかこれより大きい値の場合public int codePointBefore(int index)
char 値 (Unicode コード単位) を参照し、範囲は 1 〜 length です。
(index - 1) 位置の char 値が下位サロゲートの範囲にある場合、(index - 2) が負ではない場合、(index - 2) 位置の char 値が上位サロゲートの範囲にある場合、サロゲートペアの補助コードポイント値が返されます。index - 1 位置の char 値がペアになっていない下位または上位サロゲートの場合、サロゲート値が返されます。
index - 返されるコードポイントに続くインデックス
IndexOutOfBoundsException - index 引数が 1 未満であるか、またはこの文字列の長さより大きい値の場合
public int codePointCount(int beginIndex,
int endIndex)
String の指定されたテキスト範囲の Unicode コードポイントの数を返します。テキスト範囲は、指定された beginIndex からインデックス endIndex - 1 の位置の char までです。したがって、テキスト範囲の長さ (char 間) は、endIndex-beginIndex です。テキスト範囲内でペアになっていないサロゲートは、それぞれ 1 つのコードポイントとして数えられます。
beginIndex - テキスト範囲内の最初の char へのインデックスendIndex - テキスト範囲内の最後の char の後ろのインデックス
IndexOutOfBoundsException - beginIndex が負の値である場合、endIndex がこの String の長さより大きい場合、あるいは beginIndex が endIndex より大きい場合
public int offsetByCodePoints(int index,
int codePointOffset)
codePointOffset コードポイントによって指定された index からオフセットが設定された、この String 内のインデックスを返します。index と codePointOffset によって指定されたテキスト範囲内でペアになっていないサロゲートは、それぞれ 1 つのコードポイントとして数えられます。
index - オフセットへのインデックスcodePointOffset - コードポイント内のオフセット
String 内のインデックス
IndexOutOfBoundsException - index が負の値、またはこのString の長さよりも大きい場合、codePointOffset が正の値であり index から始まる部分文字列の持つコードポイント数が codePointOffset コードポイント数よりも少ない場合、または codePointOffset が負の値で index の前の部分文字列の持つ値が codePointOffset コードポイントの絶対値よりも小さい場合
public void getChars(int srcBegin,
int srcEnd,
char[] dst,
int dstBegin)
コピーされる最初の文字のインデックスは srcBegin、コピーされる最後の文字のインデックスは srcEnd-1 です。 したがって、コピーされる文字数は srcEnd-srcBegin となります。文字は dst の部分配列にコピーされます。 始点のインデックスは dstBegin で、終点のインデックスは次のようになります。
dstbegin + (srcEnd-srcBegin) - 1
srcBegin - コピー対象文字列内の最初の文字のインデックスsrcEnd - コピー対象文字列内の最後の文字のあとのインデックスdst - コピー先配列dstBegin - コピー先の配列内での開始オフセット
IndexOutOfBoundsException - 次のどれかに当てはまる場合
srcBegin が負
srcBegin が srcEnd より大きい
srcEnd がこの文字列の長さより大きい
dstBegin が負
dstBegin+(srcEnd-srcBegin) が dst.length よりも大きい
@Deprecated
public void getBytes(int srcBegin,
int srcEnd,
byte[] dst,
int dstBegin)
getBytes() メソッドの使用が推奨されます。
コピーされる最初の文字のインデックスは srcBegin、コピーされる最後の文字のインデックスは srcEnd-1 です。したがって、コピーされる文字数は srcEnd-srcBegin となります。文字はバイトに変換されて dst の部分配列にコピーされます。 始点のインデックスが dstBegin で、終点のインデックスは次のようになります。
dstbegin + (srcEnd-srcBegin) - 1
srcBegin - コピー対象文字列内の最初の文字のインデックスsrcEnd - コピー対象文字列内の最後の文字のあとのインデックスdst - コピー先配列dstBegin - コピー先の配列内での開始オフセット
IndexOutOfBoundsException - 次のどれかに当てはまる場合
srcBegin が負
srcBegin が srcEnd より大きい
srcEnd がこの文字列の長さより大きい
dstBegin が負
dstBegin+(srcEnd-srcBegin) が dst.length より大きい
public byte[] getBytes(String charsetName)
throws UnsupportedEncodingException
String をバイトシーケンスに符号化し、結果を新規バイト配列に格納します。
指定された文字セットでこの文字列を符号化できない場合、このメソッドの動作は指定されません。符号化処理をより強力に制御する必要がある場合、CharsetEncoder クラスを使用する必要があります。
charsetName - サポートする charset の名前
UnsupportedEncodingException - 指定された文字セットがサポートされていない場合public byte[] getBytes(Charset charset)
String をバイトシーケンスに符号化し、結果を新規バイト配列に格納します。
このメソッドは、不正入力シーケンスやマップ不可文字シーケンスを、この文字セットのデフォルトの置換バイト配列で置き換えます。符号化処理をより強力に制御する必要がある場合、CharsetEncoder クラスを使用する必要があります。
charset - String の復号化に使用される Charset
public byte[] getBytes()
String をバイトシーケンスに符号化し、結果を新規バイト配列に格納します。
デフォルトの文字セットでこの文字列を符号化できない場合、このメソッドの動作は指定されません。符号化処理をより強力に制御する必要がある場合、CharsetEncoder クラスを使用する必要があります。
public boolean equals(Object anObject)
null でなく、このオブジェクトと同じ文字シーケンスを表す String オブジェクトである場合にだけ、結果は true になります。
Object 内の equalsanObject - この String と比較されるオブジェクト
String を表す場合は true、そうでない場合は falsecompareTo(String),
equalsIgnoreCase(String)public boolean contentEquals(StringBuffer sb)
StringBuffer を比較します。この String が、指定された StringBuffer と同じ文字シーケンスを表す場合にだけ、結果は true になります。
sb - この String と比較される StringBuffer
String が、指定された StringBuffer と同じ文字シーケンスを表す場合は true、そうでない場合は falsepublic boolean contentEquals(CharSequence cs)
CharSequence を比較します。この String が、指定されたシーケンスと同じ char 値のシーケンスを表す場合にだけ、結果は true になります。
cs - この String と比較されるシーケンス
String が、指定されたシーケンスとと同じ char 値のシーケンスを表す場合は true、そうでない場合は falsepublic boolean equalsIgnoreCase(String anotherString)
String とほかの String を比較します。大文字と小文字は区別されません。長さが同じで、2 つの文字列内の対応する文字が大文字と小文字の区別なしで等しい場合、2 つの文字列は大文字と小文字の区別なしで等しいと見なされます。
次のどれかに該当する場合に、c1 と c2 という 2 つの文字は大文字小文字の区別なしで等しいと見なされます。
== 演算子による比較)
Character.toUpperCase(char) メソッドをそれぞれの文字に適用すると同じ結果になる
Character.toLowerCase(char) メソッドをそれぞれの文字に適用すると同じ結果になる
anotherString - この String と比較される String
null でなく等しい String を表す (大文字と小文字は区別しない) 場合は true、そうでない場合は falseequals(Object)public int compareTo(String anotherString)
String オブジェクトによって表される文字シーケンスが、引数文字列によって表される文字シーケンスと辞書的に比較されます。この String オブジェクトが辞書的に引数文字列より前にある場合は、結果は負の整数になります。この String オブジェクトが辞書的に引数文字列の後ろにある場合、結果は正の整数になります。文字列が等しい場合、結果は 0 になります。 equals(Object) メソッドが true を返すとき、compareTo は 0 を返します。
辞書的の順序の定義を示します。2 つの文字列が異なる場合、両方の文字列に対して有効なインデックスに位置する文字が異なるか、2 つの文字列の長さが異なるか、あるいはその両方が該当します。1 つ以上のインデックスの位置にある文字が異なる場合は、このうちのもっとも小さいインデックスを k とすると、< 演算子を使用して「より小さい」値と判定される、位置 k にある文字を持つ文字列が、もう一方の文字列より辞書的に前になります。この場合、compareTo は 2 つの文字列で位置 k にある 2 つの文字の値の差を返します。 これは次の式で表される値になります。
有効なすべてのインデックス位置における文字が同じ場合は、短い方の文字列が辞書的に前になります。この場合は、this.charAt(k)-anotherString.charAt(k)
compareTo は文字列の長さの差を返します。 これは次の式で表される値になります。
this.length()-anotherString.length()
Comparable<String> 内の compareToanotherString - 比較対象の String
0。この文字列が文字列引数より辞書式に小さい場合は、0 より小さい値。この文字列が文字列引数より辞書式に大きい場合は、0 より大きい値public int compareToIgnoreCase(String str)
compareTo を呼び出して得られた符号を持つ整数を返します。 ここでは、各文字で Character.toLowerCase(Character.toUpperCase(character)) を呼び出すことで大文字と小文字の違いがなくなります。 このメソッドはロケールを考慮しないので、一部のロケールでは、正しい順序に並べられないことがあります。java.text パッケージは、ロケールに依存する並べ替えを行うために「照合機能」を提供しています。
str - 比較対象の String
Collator.compare(String, String)
public boolean regionMatches(int toffset,
String other,
int ooffset,
int len)
この String オブジェクトの部分文字列が、引数 other の部分文字列と比較されます。これらの部分文字列が同じ文字シーケンスを表す場合、結果は true になります。比較の対象となる String オブジェクトの部分文字列は、インデックス toffset から始まり、長さは len です。比較の対象となる other の部分文字列はインデックス ooffset から始まり、長さは len です。以下のどれかに該当する場合にだけ、結果は false になります。
toffset - この文字列内の部分領域の開始オフセットother - 文字列引数ooffset - 文字列引数内の部分領域の開始オフセットlen - 比較対象の文字数
true、そうでない場合は false
public boolean regionMatches(boolean ignoreCase,
int toffset,
String other,
int ooffset,
int len)
この String オブジェクトの部分文字列が、引数 other の部分文字列と比較されます。これらの部分文字列が同じ文字シーケンスを表す場合、結果は true になります。 ignoreCase が true の場合にだけ、大文字と小文字が区別されません。比較の対象となる String オブジェクトの部分文字列は、インデックス toffset から始まり、長さは len です。比較の対象となる other の部分文字列は、インデックス ooffset から始まり、長さは len です。以下のどれかに該当する場合にだけ、結果は false になります。
this.charAt(toffset+k) != other.charAt(ooffset+k)
Character.toLowerCase(this.charAt(toffset+k)) !=
Character.toLowerCase(other.charAt(ooffset+k))
Character.toUpperCase(this.charAt(toffset+k)) !=
Character.toUpperCase(other.charAt(ooffset+k))
ignoreCase - true の場合、文字の比較の際に大文字小文字は区別されないtoffset - この文字列内の部分領域の開始オフセットother - 文字列引数ooffset - 文字列引数内の部分領域の開始オフセットlen - 比較対象の文字数
true、そうでない場合は false。一致した場合に、大文字と小文字が区別されているかどうかは引数 ignoreCase によって決まる
public boolean startsWith(String prefix,
int toffset)
prefix - 接頭辞toffset - この文字列の比較を開始する位置
toffset で始まるこのオブジェクトの部分文字列の接頭辞である場合は true、そうでない場合は false。
toffset が負の値の場合、あるいは String オブジェクトの長さより大きい場合、結果は false。 そうでない場合は、結果は次の式の結果と同じ
this.substring(toffset).startsWith(prefix)
public boolean startsWith(String prefix)
prefix - 接頭辞
true、そうでない場合は false。
引数が空の文字列の場合や、equals(Object) メソッドによる判定においてこの String オブジェクトに等しい場合にも true が返されるpublic boolean endsWith(String suffix)
suffix - 接尾辞
true、そうでない場合は false。引数が空の文字列の場合や、equals(Object) メソッドによる判定においてこの String オブジェクトに等しい場合にも、結果は true になるpublic int hashCode()
String のハッシュコードは、次の方法で計算します。
s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
int 算術を使います。 s[i] は文字列の i 番目の文字、n は文字列の長さ、^ は、べき乗を示します。空の文字列のハッシュ値は 0 です。
Object 内の hashCodeObject.equals(java.lang.Object),
Hashtablepublic int indexOf(int ch)
ch を持つ文字がこの String オブジェクトによって表される文字シーケンス内にある場合、最初に出現する位置のインデックス (Unicode コード単位) が返されます。ch の値が 0 〜 0xFFFF の範囲にある場合、次の式が true となるような最小値 k が返されます。
true です。this.charAt(k) == ch
ch がほかの値の場合、次の式が true となるような最小値 k です。
true です。該当する文字がこの文字列内にない場合は、this.codePointAt(k) == ch
-1 が返されます。
ch - 文字 (Unicode コードポイント)
-1
public int indexOf(int ch,
int fromIndex)
値 ch を持つ文字が、この String オブジェクトによって表される文字シーケンスの fromIndex より大きいか同じインデックス位置にある場合、該当する最初のインデックスが返されます。ch の値が 0 〜 0xFFFF の範囲にある場合、次の式が true となるような最小値 k が返されます。
true です。(this.charAt(k) == ch) && (k >= fromIndex)
ch がほかの値の場合、次の式が true となるような最小値 k です。
true です。該当する文字がこの文字列内または位置(this.codePointAt(k) == ch) && (k >= fromIndex)
fromIndex 以降にない場合は -1 が返されます。
fromIndex の値に対して制約はない。負の値の場合は、0 の場合と同じ結果になり、この文字列全体が検索されます。この文字列の長さより大きい場合は、この文字列の長さに等しい場合と同じ結果になり、-1 が返されます。
すべてのインデックスは、char 値 (Unicode コード単位) で指定されます。
ch - 文字 (Unicode コードポイント)fromIndex - 検索開始位置のインデックス
fromIndex と同じかこれより大きいインデックス位置にある場合は、最初に出現した位置のインデックス。文字がない場合は -1public int lastIndexOf(int ch)
ch 値が 0 〜 0xFFFF の範囲にある場合、返されるインデックス (Unicode コード単位) は、次の式に該当する最大値 k です。
true です。this.charAt(k) == ch
ch がほかの値の場合、次の式に該当する最大値 k です。
true です。該当する文字がこの文字列内にない場合は、this.codePointAt(k) == ch
-1 が返されます。String の検索は最後の文字から開始され、先頭方向に行われます。
ch - 文字 (Unicode コードポイント)
-1
public int lastIndexOf(int ch,
int fromIndex)
ch 値が 0 〜 0xFFFF の範囲にある場合、返されるインデックスは、次の式に該当する最大値 k です。
true です。(this.charAt(k) == ch) && (k <= fromIndex)
ch がほかの値の場合、次の式に該当する最大値 k です。
true です。該当する文字がこの文字列内または位置(this.codePointAt(k) == ch) && (k <= fromIndex)
fromIndex 以前にない場合は -1 が返されます。
すべてのインデックスは、char 値 (Unicode コード単位) で指定されます。
ch - 文字 (Unicode コードポイント)fromIndex - 検索開始位置のインデックスfromIndex の値に対して制約はない。
この文字列の長さと同じかこれより大きい場合は、この文字列の長さより 1 小さい場合と同じ結果になり、この文字列全体が検索される。
負の値の場合は、-1 の場合と同じ結果になり、-1 が返される
fromIndex と同じかこれより小さいインデックス位置に最後に出現する位置のインデックス。指定された文字がその位置より前にない場合は -1public int indexOf(String str)
this.startsWith(str, k)
true です。
str - 任意の文字列
-1
public int indexOf(String str,
int fromIndex)
k >= Math.min(fromIndex, this.length()) && this.startsWith(str, k)
str - 検索対象の部分文字列fromIndex - 検索開始位置のインデックス
public int lastIndexOf(String str)
this.length() と見なされます。返されるインデックスは、
上の式がthis.startsWith(str, k)
true となるような最大の k です。
str - 検索対象の部分文字列
-1
public int lastIndexOf(String str,
int fromIndex)
k <= Math.min(fromIndex, this.length()) && this.startsWith(str, k)
str - 検索対象の部分文字列fromIndex - 検索開始位置のインデックス
public String substring(int beginIndex)
例:
"unhappy".substring(2) returns "happy" "Harbison".substring(3) returns "bison" "emptiness".substring(9) returns "" (an empty string)
beginIndex - 開始インデックス (この値を含む)
IndexOutOfBoundsException - beginIndex が負の値の場合、あるいはこの String オブジェクトの長さより大きい場合
public String substring(int beginIndex,
int endIndex)
beginIndex から始まり、インデックス endIndex - 1 にある文字までです。したがって、部分文字列の長さは endIndex-beginIndex になります。 例:
"hamburger".substring(4, 8) returns "urge" "smiles".substring(1, 5) returns "mile"
beginIndex - 開始インデックス (この値を含む)endIndex - 終了インデックス (この値を含まない)
IndexOutOfBoundsException - beginIndex が負の値である場合、endIndex がこの String オブジェクトの長さより大きい場合、あるいは beginIndex が endIndex より大きい場合
public CharSequence subSequence(int beginIndex,
int endIndex)
次のフォームのメソッド呼び出しは、
次の呼び出しと正確に同じ動作になります。str.subSequence(begin, end)
このメソッド定義により、String クラスがstr.substring(begin, end)
CharSequence インタフェースを実装可能になります。
CharSequence 内の subSequencebeginIndex - 開始インデックス (この値を含む)endIndex - 終了インデックス (この値を含まない)
IndexOutOfBoundsException - beginIndex または endIndex が負の値の場合、endIndex の値が length() より大きい場合、beginIndex の値が startIndex よりも大きい場合public String concat(String str)
引数文字列の長さが 0 の場合は、この String オブジェクトが返されます。そうでない場合は、この String オブジェクトによって表される文字列と引数文字列によって表される文字列とを連結したものを表す新しい String オブジェクトが生成されます。
例:
"cares".concat("s") returns "caress"
"to".concat("get").concat("her") returns "together"
str - この String の最後に連結される String
public String replace(char oldChar,
char newChar)
oldChar を newChar に置換した結果生成される、新しい文字列を返します。
文字 oldChar がこの String オブジェクトによって表される文字列内にない場合は、この String オブジェクトへの参照が返されます。そうでない場合は、この String オブジェクトによって表される文字列と同じ文字列を表す、新しい String オブジェクトが生成されます。 ただし、文字列内の oldChar はすべて newChar に置換されます。
例:
"mesquite in your cellar".replace('e', 'o')
returns "mosquito in your collar"
"the war of baronets".replace('r', 'y')
returns "the way of bayonets"
"sparring with a purple porpoise".replace('p', 't')
returns "starring with a turtle tortoise"
"JonL".replace('q', 'x') returns "JonL" (no change)
oldChar - 以前の文字newChar - 新しい文字
oldChar を newChar に置換することによって生成された文字列public boolean matches(String regex)
このフォームのメソッド呼び出し str.matches(regex) では、次の式と正確に同じ結果が得られます。
Pattern.matches(regex, str)
regex - この文字列との一致を判定する正規表現
PatternSyntaxException - 正規表現の構文が無効な場合Patternpublic boolean contains(CharSequence s)
s - 検索するシーケンス
s を含む場合は true。 そうでない場合は false
NullPointerException - s が null の場合
public String replaceFirst(String regex,
String replacement)
このフォームのメソッド呼び出し str.replaceFirst(regex, repl) では、次の式と正確に同じ結果が得られます。
Pattern.compile(regex).matcher(str).replaceFirst(repl)
置換文字列内でバックスラッシュ (\) とドル記号 ($) を使用すると、それをリテラル置換文字列として処理した場合とは結果が異なる場合があります。Matcher.replaceFirst(java.lang.String) を参照してください。必要に応じて、Matcher.quoteReplacement(java.lang.String) を使用して、これらの文字に特別な意味を持たせないようにしてください。
regex - この文字列との一致を判定する正規表現replacement - 最初に一致するものに置き換えられる文字列
PatternSyntaxException - 正規表現の構文が無効な場合Pattern
public String replaceAll(String regex,
String replacement)
このフォームのメソッド呼び出し str.replaceAll(regex, repl) では、次の式と正確に同じ結果が得られます。
Pattern.compile(regex).matcher(str).replaceAll(repl)
置換文字列内でバックスラッシュ (\) とドル記号 ($) を使用すると、それをリテラル置換文字列として処理した場合とは結果が異なる場合があります。Matcher.replaceAll を参照してください。必要に応じて、Matcher.quoteReplacement(java.lang.String) を使用して、これらの文字に特別な意味を持たせないようにしてください。
regex - この文字列との一致を判定する正規表現replacement - 一致するものそれぞれに置き換えられる文字列
PatternSyntaxException - 正規表現の構文が無効な場合Pattern
public String replace(CharSequence target,
CharSequence replacement)
target - 置換される char 値のシーケンスreplacement - char 値の置換シーケンス
NullPointerException - target または replacement が null の場合
public String[] split(String regex,
int limit)
この文字列の各部分文字列を含むメソッドにより返される配列は、指定された式に一致する別の部分文字列、またはその文字列の最後で終了します。配列内の部分文字列の順序は、この文字列内で出現する順序になります。入力されたどの部分とも式が一致しない場合、配列は 1 つの要素 (つまり、この文字列) だけを保持します。
limit パラメータは、このパターンの適用回数、つまり、結果として得られる配列の長さを制御します。制限 n がゼロより大きい場合、このパターンは n - 1 回以下の回数が適用され、配列の長さは n 次のようになります。 配列の最後のエントリには、最後にマッチした区切り文字以降の入力シーケンスがすべて含まれます。n が負の値の場合、このパターンの適用回数と配列の長さは制限されません。n がゼロの場合、このパターンの適用回数と配列の長さは制限されませんが、後続の空の文字列は破棄されます。
たとえば、次のパラメータが指定された場合の、文字列 "boo:and:foo" の結果を示します。
正規表現 制限 結果 : 2 { "boo", "and:foo" } : 5 { "boo", "and", "foo" } : -2 { "boo", "and", "foo" } o 5 { "b", "", ":and:f", "", "" } o -2 { "b", "", ":and:f", "", "" } o 0 { "b", "", ":and:f" }
このフォームのメソッド呼び出し str.split(regex, n) では、次の式と正確に同じ結果が得られます。
Pattern.compile(regex).split(str, n)
regex - 正規表現の区切りlimit - 結果のしきい値 (上記を参照)
PatternSyntaxException - 正規表現の構文が無効な場合Patternpublic String[] split(String regex)
このメソッドの動作は、2 つの引数を取る split メソッドを、指定された式および引数制限ゼロを指定して呼び出した場合と同じになります。つまり、結果として得られる配列には後続の空の文字列は含まれません。
たとえば、次の式を指定した場合の、文字列 "boo:and:foo" の結果を示します。
正規表現 結果 : { "boo", "and", "foo" } o { "b", "", ":and:f" }
regex - 正規表現の区切り
PatternSyntaxException - 正規表現の構文が無効な場合Patternpublic String toLowerCase(Locale locale)
Locale の規則を使用して、この String 内のすべての文字列を小文字に変換します。ケースマッピングは、Character クラスで指定された Unicode 仕様バージョンに基づいています。ケースマッピングは常に 1:1 の文字マッピングになるとは限らないため、結果として得られる String が元の String と長さが異なる場合があります。 小文字のマッピング例を、次の表に示します。
| ロケールの言語コード | 大文字 | 小文字 | 説明 |
|---|---|---|---|
| tr (トルコ語) | \u0130 | \u0069 | 上に点が付いた大文字の I -> 小文字の i |
| tr (トルコ語) | \u0049 | \u0131 | 大文字の I -> 点のない小文字の i |
| (すべて) | French Fries | french fries | String 内の文字すべてを小文字に変換 |
| (すべて) | 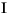 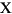  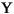 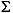 |
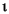 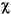 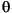 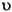 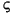 |
String 内の文字すべてを小文字に変換 |
locale - このロケールの大文字小文字変換規則を使用する
StringtoLowerCase(),
toUpperCase(),
toUpperCase(Locale)public String toLowerCase()
String 内のすべての文字を小文字に変換します。これは、toLowerCase(Locale.getDefault()) の呼び出しと等価になります。
注: このメソッドはロケールに依存するため、ロケールが単独で解釈されるような文字列に使用すると、予期せぬ結果を引き起こすことがあります。例として、プログラミング言語識別子、プロトコルキー、HTML タグがあります。たとえば、トルコ語ロケールの "TITLE".toLowerCase() は "t?tle" を返します。ここで、「?」は点のないラテン小文字の I の文字です。ロケールに依存しない文字列の正しい結果を取得するには、toLowerCase(Locale.ENGLISH) を使用します。
StringtoLowerCase(Locale)public String toUpperCase(Locale locale)
Locale の規則を使用して、この String 内のすべての文字列を大文字に変換します。ケースマッピングは、Character クラスで指定された Unicode 仕様バージョンに基づいています。ケースマッピングは常に 1:1 の文字マッピングになるとは限らないため、結果として得られる String が元の String と長さが異なる場合があります。 ロケール依存および 1:M のケースマッピングの例を、次の表に示します。
| ロケールの言語コード | 小文字 | 大文字 | 説明 |
|---|---|---|---|
| tr (トルコ語) | \u0069 | \u0130 | 小文字の i -> 上に点が付いた大文字の I |
| tr (トルコ語) | \u0131 | \u0049 | 点のない小文字の i -> 小文字の I |
| (すべて) | \u00df | \u0053 \u0053 | 小文字のシャープ s -> SS の 2 文字 |
| (すべて) | Fahrvergnügen | FAHRVERGNÜGEN |
locale - このロケールの大文字小文字変換規則を使用する
StringtoUpperCase(),
toLowerCase(),
toLowerCase(Locale)public String toUpperCase()
String 内のすべての文字を大文字に変換します。このメソッドは、toUpperCase(Locale.getDefault()) と等価になります。
注: このメソッドはロケールに依存するため、ロケールが単独で解釈されるような文字列に使用すると、予期せぬ結果を引き起こすことがあります。例として、プログラミング言語識別子、プロトコルキー、HTML タグがあります。たとえば、トルコ語ロケールの "title".toUpperCase() は "T?TLE" を返します。ここで、「?」は上に点が付いたラテン大文字の I の文字です。ロケールに依存しない文字列の正しい結果を取得するには、toUpperCase(Locale.ENGLISH) を使用します。
StringtoUpperCase(Locale)public String trim()
この String オブジェクトが空の文字列を表す場合、あるいはこの String オブジェクトによって表される文字列の最初と最後の文字のコードがいずれも '\u0020' (スペース文字) より大きい場合は、この String オブジェクトへの参照が返されます。
文字列内に '\u0020' より大きいコードの文字がない場合は、空の文字列を表す新しい String オブジェクトが生成されて返されます。
たとえば、k が文字列内の最初の文字のインデックスであり、「\u0020」より大きいコード値を持ち、m が文字列内の最後の文字のインデックスであり、「\u0020」より大きいコード値を持つ場合は、インデックス k にある文字で始まり、インデックス m にある文字で終わる、この文字列の部分文字列を表す新しい String オブジェクトが生成されます。つまり、これは this.substring(k, m+1) の結果と同じです。
このメソッドは文字列の先頭と最後から (上記で定義された) 空白を切り取るために使用できます。
public String toString()
CharSequence 内の toStringObject 内の toStringpublic char[] toCharArray()
public static String format(String format,
Object... args)
常に使用されるロケールは、Locale.getDefault() により返されるロケールです。
format - 書式文字列args - 書式文字列内の書式指示子により参照される引数。
書式指示子以外にも引数が存在する場合、余分の引数は無視される。
引数の数は変動し、ゼロの場合もある。
引数の最大数は、Java 仮想マシン仕様で定義された Java 配列の最大サイズの制限を受ける。null 引数での動作は、変換に応じて異なる
IllegalFormatException - 書式文字列に不正な構文、指定された引数と互換性のない書式指示子、引数の指定が不十分な書式文字列、またはほかの不正な条件が含まれる場合。可能性のある書式エラーすべての詳細は、Formatter クラス仕様の「詳細」セクションを参照
NullPointerException - format が null の場合Formatter
public static String format(Locale l,
String format,
Object... args)
l - 書式設定時に適用する ロケール。
l が null の場合、ローカリゼーションは適用されない。format - 書式文字列args - 書式文字列内の書式指示子により参照される引数。
書式指示子以外にも引数が存在する場合、余分の引数は無視される。
引数の数は変動し、ゼロの場合もある。
引数の最大数は、Java 仮想マシン仕様で定義された Java 配列の最大サイズの制限を受ける。null 引数での動作は、変換に応じて異なる
IllegalFormatException - 書式文字列に不正な構文、指定された引数と互換性のない書式指示子、引数の指定が不十分な書式文字列、またはほかの不正な条件が含まれる場合。考えられるすべての書式エラーの仕様については、フォーマッタクラス仕様の「詳細」のセクションを参照
NullPointerException - format が null の場合Formatterpublic static String valueOf(Object obj)
Object 引数の文字列表現を返します。
obj - Object
null の場合は、"null" に等しい文字列。そうでない場合は、obj.toString() の値Object.toString()public static String valueOf(char[] data)
char 配列引数の文字列表現を返します。文字配列の内容がコピーされます。 コピー後にその文字が変更されても、新しく作成された文字列には影響しません。
data - char 配列
public static String valueOf(char[] data,
int offset,
int count)
char 配列引数の特定の部分配列の文字列表現を返します。
offset 引数は部分配列の最初の文字のインデックスを表します。count 引数は部分配列の長さを表します。部分配列の内容がコピーされます。 コピー後に文字配列が変更されても、新しく作成された文字列には影響しません。
data - 文字配列offset - String の値への初期オフセットcount - String の値の長さ
IndexOutOfBoundsException - offset が負の値の場合、count が負の値の場合、あるいは offset+count が data.length より大きい場合
public static String copyValueOf(char[] data,
int offset,
int count)
data - 文字配列offset - 部分配列の初期オフセットcount - 部分配列の長さ
Stringpublic static String copyValueOf(char[] data)
data - 文字配列
Stringpublic static String valueOf(boolean b)
boolean 引数の文字列表現を返します。
b - boolean
true の場合は、"true" に等しい文字列。そうでない場合は、"false" に等しい文字列public static String valueOf(char c)
char 引数の文字列表現を返します。
c - char
c が格納された、長さ 1 の文字列public static String valueOf(int i)
int 引数の文字列表現を返します。
この表現は 1 つの引数を持つ Integer.toString メソッドによって返されるものとまったく同じです。
i - int
int 引数の文字列表現Integer.toString(int, int)public static String valueOf(long l)
long 引数の文字列表現を返します。
この表現は 1 つの引数を持つ Long.toString メソッドによって返されるものとまったく同じです。
l - long
long 引数の文字列表現Long.toString(long)public static String valueOf(float f)
float 引数の文字列表現を返します。
この表現は 1 つの引数を持つ Float.toString メソッドによって返されるものとまったく同じです。
f - float
float 引数の文字列表現Float.toString(float)public static String valueOf(double d)
double 引数の文字列表現を返します。
この表現は 1 つの引数を持つ Double.toString メソッドによって返されるものとまったく同じです。
d - double
double 引数の文字列表現Double.toString(double)public String intern()
文字列のプールは、初期状態では空で、String クラスによってプライベートに保持されます。
intern メソッドが呼び出されたときに、equals(Object) メソッドによってこの String オブジェクトに等しいと判定される文字列がプールにすでにあった場合は、プール内の該当する文字列が返されます。そうでない場合は、この String オブジェクトがプールに追加され、この String オブジェクトへの参照が返されます。
このため、任意の 2 つの文字列 s と t においては、s.equals(t) が true の場合にのみ、s.intern() == t.intern() は true になります。
すべてのリテラル文字列および文字列値定数式が保持されます。文字列リテラルは、『Java 言語仕様』の §3.10.5 で定義されています。
|
JavaTM Platform Standard Ed. 6 |
|||||||||
| 前のクラス 次のクラス | フレームあり フレームなし | |||||||||
| 概要: 入れ子 | フィールド | コンストラクタ | メソッド | 詳細: フィールド | コンストラクタ | メソッド | |||||||||
Copyright 2006 Sun Microsystems, Inc. All rights reserved. Use is subject to license terms. Documentation Redistribution Policy も参照してください。